Python Pandas 파이썬 판다스 간단하게 데이터 파악하기
데이터 분석을 본격적으로 하기 전에 간단하게 데이터의 형태나 정보, 통계량, 변수별 상관관계, 변수별 레이블 종류 및 개수를 확인해보자.
c.f. 예시를 들기 위하여 데이터는 데이콘의 신용카드 사용자 연체 예측 AI 경진대회 데이터셋을 사용하였다.
📌 데이터프레임.shape
데이터셋의 형태를 확인하기 위해 사용한다.
i.e. train 데이터셋에 대하여 shape 적용
train.shape실행결과
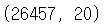
📌 데이터프레임.info()
데이터셋에 존재하는 컬럼명과 컬럼별 결측치, 컬럼별 데이터타입을 확인할 때 사용한다.
i.e. train 데이터셋에 대하여 info() 적용
train.info()실행결과

📌 데이터프레임.describe()
데이터셋의 수치형 컬럼별 주요 통계량을 summary할 때 사용한다.
i.e. train 데이터셋에 대하여 describe() 적용
train.describe()실행결과

📌 데이터프레임.corr()
데이터셋에 존재하는 컬럼간의 수치적 상관관계를 확인할 때 사용한다. 이 때, 상관계수는 -1 ~ 1 사이의 값을 가지며, 상관계수의 부호는 상관관계의 방향이고 절대값은 상관관계의 강도를 의미한다.
i.e. train 데이터셋에 대하여 corr() 적용
train.corr()실행결과

i.e. train 데이터셋의 다른 컬럼과 target 사이의 상관관계를 알아보기 위하여 corr() 적용
train.corr()['credit']실행결과

📌 데이터프레임.nunique()
데이터셋에 존재하는 컬럼별 레이블의 개수를 확인하기 위해 사용한다.
i.e. train 데이터셋에 대하여 nunique() 적용
train.nunique()실행결과

📌 컬럼.value_counts()
컬럼에 포함된 레이블의 종류 및 개수를 확인하기 위해 사용한다. 참고로 unique() 를 사용하면 컬럼 내에 존재하는 모든 레이블의 종류가 나오고, nunique() 를 사용하면 컬럼 내에 존재하는 레이블의 개수가 나오는데 value_counts()는 unique()와 nunique()를 종합한 것이라고 볼 수 있다.
i.e. train 데이터셋에 존재하는 범주형 변수에 대하여 nunique() 적용
cat_col = train.columns[train.dtypes == object]
for col in cat_col:
print(train[col].value_counts())
print('=' * 50)실행결과

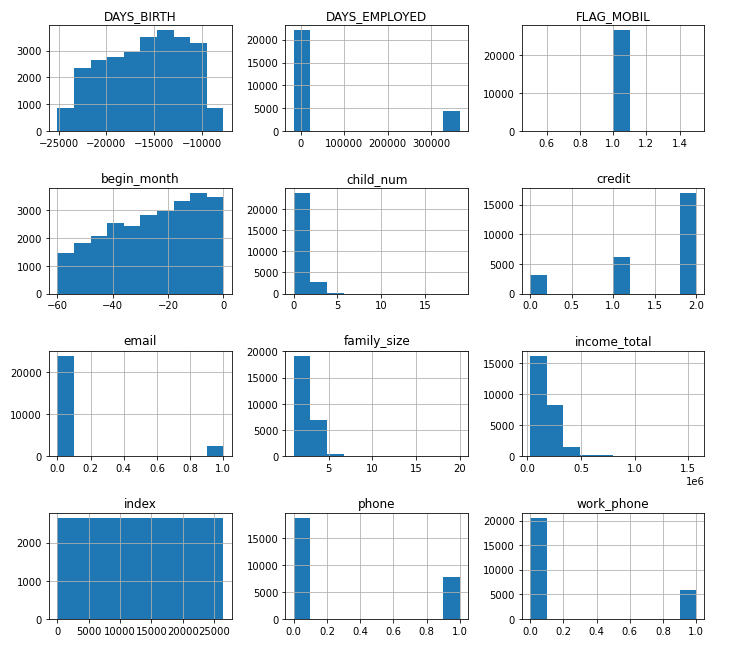
📌 데이터프레임.hist()
데이터프레임의 컬럼별 히스토그램을 시각화할 수 있다.
i.e. train 데이터셋에 대하여 hist() 적용
import seaborn as sns
import matplotlib.pyplot as plt
train.hist(figsize=(10, 9))
plt.tight_layout()
plt.show()실행결과
내용이 도움이 되셨다면 댓글 또는 좋아요 부탁드립니다. 감사합니다. 😀
'공부 > code' 카테고리의 다른 글
| [Python] Pandas : 자주 사용하는 데이터프레임 display 옵션 4가지 정리 (0) | 2021.03.27 |
|---|---|
| [Python] Pandas : 데이터프레임에서 생략된 rows(행)과 columns(열) 다 보이게 하기 (0) | 2021.02.28 |
| [Python] Pandas : loc 과 iloc 의 차이 (2) | 2021.02.19 |
| [Python] 폴더 안의 모든 하위 파일 복사해서 하나의 폴더로 합치기 코드 (Copy Files from Multiple Subfolders to a Merged Folder) (5) | 2020.12.20 |



