🗒️ LLM Provider 정리 및 선택 가이드
(ChatGPT, Claude, Gemini, HyperCLOVA, LLaMA 등)
📌 개요

ChatGPT, Claude, Gemini, HyperCLOVA, LLaMA 등 수많은 고성능의 LLM이 등장하면서 모델 선택지가 넓어졌다. 그러나 동시에 어떤 모델을 써야할 지 고민이 되는 것도 사실이다. 모델마다 태스크 퍼포먼스, 응답 속도, 비용 등이 다르기 때문에 용도나 가용 자원에 맞는 LLM을 고르는 것이 중요하다. 그래서 이번 포스팅에서는 LLM 플래그쉽 모델들을 위주로 비교하여 설명하고자 한다.
📌 어떤 모델을 선택할까?
✔ 기준
LLM 성능 수준 비교, 특징 및 장단점, 비용, 토큰수, 사용 가능한 툴(인터넷 액세스, 코드 인터프리터, 이미지 등), 커뮤니티 크기, 파라미터 크기 등을 전반적으로 고려.
✔ 중요하게 고려할 요소
1.성능 및 정확도 : 다양한 벤치마크 테스트 결과와 실제 사용 경험을 통해 각 모델의 정확도와 품질 평가 필요
2. 특징 및 기능 : 각 모델의 고유한 특징, 지원하는 기능 (인터넷 액세스, 코드 인터프리터, 이미지 처리 등) 고려
3. 비용이나 응답 속도 : 특히 대규모 사용 시 비용 효율성이 중요
이러한 3가지 요소에 초점을 맞추어 다양한 LLM을 비교해보도록 할 예정이다.
📌 성능
✔ 벤치마크

일단 LLM의 성능을 알려면 벤치마크를 참고할 필요가 있다. 흔히 대표적인 벤치마크는 ARC, HellaSwag, MMLU, TruthfulQA, Winogrande, GSM8k 등이 있다. 이 때 벤치마크 성능은 절대적인 지표라기보다는, 어디까지나 참고 용도라는 점을 유의할 필요가 있다. 벤치마크들은 특정 데이터 세트를 기반으로 평가되므로 실제 다양한 상황에서의 성능을 완전히 반영하지 못할 수 있기 때문이다. 그래서 특정 도메인이나 상황에서는 벤치마크 점수가 높은 모델도 성능이 떨어질 수 있고 벤치마크 데이터셋의 편향으로 인해 모델 성능이 왜곡될 수 있으며 평가에 사용된 데이터가 모델 학습에 포함되면 성능이 과대평가될 수 있어서 오염 가능성이 있다. 따라서 모델의 전반적인 강약점 파악이나 성능이 어느 정도 수준이 되는지 정도만 참고하는 것이 권장된다.
✔ LMSYS Chatbot Arena
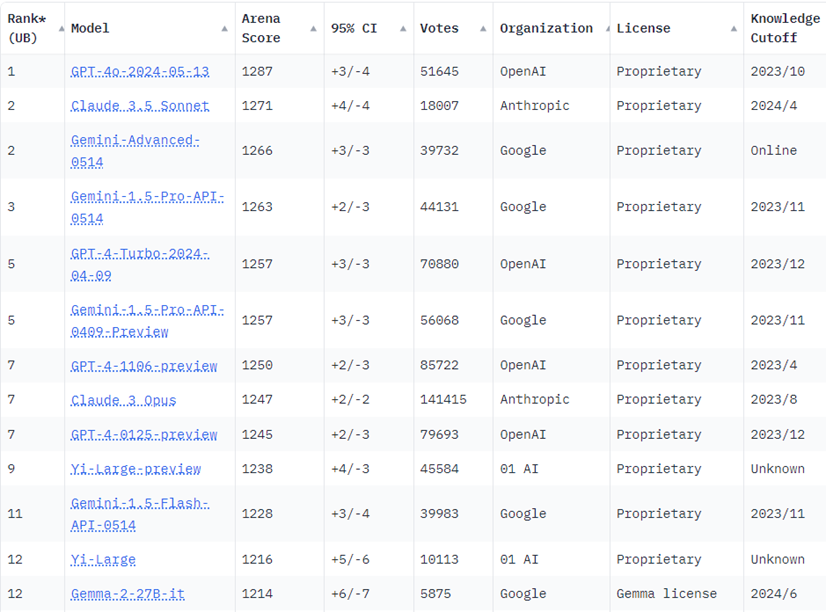
성능을 확인할 때에는 LMSYS Chatbot Arena 리더보드를 확인하는 것을 추천한다. 이 리더보드는 블라인드 상태에서 LLM 성능을 상대적으로 비교, 평가하기 위한 크라우드소싱 방식의 벤치마크 플랫폼이다. 사용자는 블라인드 상태에서 두가지 다른 LLM 출력 결과 중 더 성능이 좋다고 판단되는 LLM에게 투표를 하며, 사용자 투표를 통해 축적된 점수를 통해 LLM의 순위가 산정된다. 사람이 직접 비교하고 평가하여 순위를 매긴 것이므로 다른 벤치마크들보다 더 실제 체감 성능이 align되는 편이다. 따라서 모델 성능을 고려할 때엔 Chatbot Arena 리더보드 순위를 확인하는 것을 권장한다.
현재 블로그 포스팅에 사용한 캡쳐는 2024.07.05 기준 순위인데 GPT-4o가 가장 높은 순위이고 최근 나온 Claude 3.5 sonnet, 그리고 Gemini Advanced가 나란히 1, 2, 3위를 한 걸 확인할 수 있다. 실제로 LLM을 쓰면서 느낀 체감 성능도 이 순위와 일치하는 것 같다.
📌 기능 및 특징
| ChatGPT | Claude | Gemini | HyperCLOVA | LLaMA | |
| 제조사 | OpenAI | Anthropic | Naver | Meta | |
| 플래그쉽 모델 라인업 | GPT-4o, GPT-4-turbo, GPT-4, GPT-3.5-turbo | Claude 3.5 Sonnet, Claude 3 Opus, Sonnet, Haiku |
Gemini 1.5 Pro, Gemini 1.0 Ultra | HCX-003, HCX-DASH-001 |
Llama 3 8B, 70B, 400+B(training) |
| 파라미터 크기 | 비공개 (GPT-3의 경우 1750억개였고 GPT-4는 그보다 훨씬 큰 것으로 추정. 오피셜은 아니지만 5,000억~1조개로 추정됨) |
비공개 | 비공개 (GPT-4보다 파라미터 크기가 큰 것으로 알려져 있지만 구체적 수치는 밝혀져 있지 않음) | 비공개 | 8b, 70b, 400+b |
| 지식 컷오프(지식을 언제까지 학습했는지) | GPT-4o: 2023.10 GPT-4-turbo : 2023.12 GPT-4 : 2021.09 GPT-3.5-turbo: 2021.09 |
Claude 3.5 Sonnet: 2024.04 Claude3 Opus: 2023.08 Claude 3 Sonnet: 2023.08 Claude 3 Haiku: 2023.08 |
오피셜하게 나오지 않음. 기본적으로 Gemini는 답변 시에 지시와 관련한 내용을 구글 검색하여 최신 지식을 context에 추가. | HCX-003 : 2023.12 HCX-DASH-001 : 2023.12 |
8B : 2023.03 70B : 2023.12 |
| 입력 | 멀티모달(텍스트, 이미지, 오디오, 비디오 등) | 멀티모달(텍스트, 이미지 등) | 멀티모달(텍스트, 이미지, 오디오, 비디오 등) | 텍스트 | 텍스트 |
| 출력 | 텍스트, 이미지(DALLE) | 텍스트 | 텍스트, 이미지 | 텍스트 | 텍스트 |
| 컨텍스트 윈도우 크기 (가장 큰 엔진 기준) | 128k (12만 8천 토큰) | 200k (20만 토큰, 약 150,000단어) | 1m (100만 토큰) | 4k (4096 토큰) | 8k (8192 토큰) |
| 특징 | 1. knowlege base를 사용하여 커스텀 GPT 만들어 사용 가능 2. 4o 모델을 통해 오디오 기능 통합 3. 워크플로우에 통합할 때 범용적으로 좋은 퀄리티 4. 인터넷 액세스 (빙 서치) 5. 유저 커뮤니티 활성화 |
1. 최신 출시된 아티팩트를 활용하여 코드, 이미지, ppt 등 활용 가능성 풍부 2. 창의적 글쓰기 3. 윤리성 |
1. Gmail, Docs 등에서 Gemini 이용 가능 2. 구글 서치를 통한 팩트체킹 가능 3. 유튜브나 url 액세스 가능 4. 텍스트와 이미지를 멀티모달로 처리하는 능력이 우수 |
1. 대한민국 국가/정치적 지식에 대한 높은 이해도 2. 대한민국 법률 관련 지식 |
1. 오픈소스 2. 파인튜닝 등에 많이 활용 |


각 LLM별 기능 및 특징을 도표로 정리해 보았다. 지식 컷오프, 입출력 형식, 컨텍스트 윈도우, 그리고 각종 특징을 통해 LLM을 선택하는 과정에서 참고해볼 수 있다.
📌 비용
| 모델 | 입력 가격 (1M 토큰당) | 출력 가격 (1M 토큰당) |
| gpt-4o | $5.00 (약 6,500원) | $15.00 (약 19,500원) |
| gpt-4-turbo | $10.00 (약 13,000원) | $30.00 (약 39,000원) |
| gpt-3.5-turbo-0125 | $0.50 (약 650원) | $1.50 (약 1,950원) |
| gpt-4 | $30.00 (약 39,000원) | $60.00 (약 78,000원) |
| gpt-4-32k | $60.00 (약 78,000원) | $120.00 (약 156,000원) |
| Gemini 1.5. Pro | \$3.50 (128K 이하) (약 4,550원), $7.00 (128K 초과) (약 9,100원) |
\$10.50 (128K 이하) (약 13,650원), $21.00 (128K 초과) (약 27,300원) |
| Gemini 1.5. Flash | \$0.35 (128K 이하) (약 455원), $0.70 (128K 초과) (약 910원) |
\$1.05 (128K 이하) (약 1,365원), $2.10 (128K 초과) (약 2,730원) |
| Claude 3.5 Sonnet | $3.00 (약 3,900원) | $15.00 (약 19,500원) |
| Claude 3 Opus | $15.00 (약 19,500원) | $75.00 (약 97,500원) |
| Claude 3 Haiku | $0.25 (약 325원) | $1.25 (약 1,625원) |
| HyperCLOVA HCX-003 | 5,000원 | 5,000원 |
| HyperCLOVA HCX-DASH-001 | 1,000원 | 1,000원 |

그리고 LLM의 API 호출 시에는 비용이 발생하는데, 그 비용도 도표로 정리해보았다. 100만 토큰 기준으로 비용을 산정했고, 원달러 환율을 1300원으로 계산해서 한화로도 표시를 하였다. 이 API 호출 비용은 2024.07.06 기준이다.
📌 마무리
LLM을 목적에 맞게 잘 활용하거나 개발하기 위하여, 다양한 LLM의 특징과 장단점을 파악하고 상황에 맞는 최적의 모델을 선택할 수 있도록 가이드 글을 작성해보았다. 이러한 모델의 성능, 기능 및 특징, 비용 등의 기준으로 비교해보면서 원하는 목적의 태스크를 수행하기에 적합한 모델을 선택해볼 수 있다.
'공부 > AI' 카테고리의 다른 글
| [LLM Evaluation] LLM 성능 평가 방법 : Metric, Benchmark, LLM-as-a-judge 등 (0) | 2024.05.21 |
|---|---|
| [회고] 글또 9기 : 개발자 글쓰기 모임을 통해 어떤 것을 얻었을까? (5) | 2024.05.12 |
| [Project] 프롬프트 엔지니어링 사이드 프로젝트 개발기 (6) | 2024.04.04 |
| [논문리뷰] Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4 (2024) (6) | 2024.03.11 |
| [Prompt] 프롬프트 엔지니어는 어떤 일을 할까? 나의 업무 소개 (6) | 2024.02.18 |



