📚 [비전] GoogLeNet (Inception V1) 논문 리뷰 및 요약
📌 개요
✔ GoogLeNet (Inception V1) 논문 키포인트
1. 네트워크의 depth와 width를 증가시키면서 파라미터는 오히려 이전보다 줄일 수 있는 효율적인 인셉션 모듈 고안.
2. 1x1 convolutions를 사용하는 bottleneck layers 도입하여 차원 축소 및 연산량 감소, 비선형성 효과 달성.
3. Global Average Pooling 레이어 사용.
4. ILSVRC 2014에서 1위를 차지하였으며 top-5 error rate 6.7% 달성.
📌 sparsely connected 구조의 필요성과 현재 하드웨어의 연산 방식에 따른 고려사항
✔ 네트워크에서 sparsely connected 구조의 필요성
1. deep neural networks의 성능을 증가시키는 방법은 depth(레이어의 개수)를 늘리는 것, 그리고 width(각 레이어의 units의 개수)를 늘리는 것이다.
2. 그러나 이렇게 네트워크의 size를 크게할수록 파라미터가 증가하고 overfitting 문제와 컴퓨팅 리소스의 소모 문제가 발생한다.
3. 이러한 문제의 해결방법은 sparsely connected architectures를 사용하는 것이다. 그러나 네트워크가 작동하는 하드웨어의 연산 방식을 고려해야 한다.
✔ 현재 하드웨어의 연산 방식에 따른 고려사항
1. 현재의 하드웨어는 비정형적이고 sparse한 데이터 구조에 대하여 연산을 하기에 비효율적이다. 특히 dense 매트릭스 연산을 빠르게 하도록 만들어진 최근의 라이브러리들은 sparse한 데이터 연산을 더욱 더 비효율적으로 만든다.
2. 따라서 네트워크 구조에서 sparsity를 확보하되, dense 매트릭스 연산에 적합한 현재의 하드웨어에서 작동할 수 있는 구조를 고안해야 한다.
3. 이를 위해 네트워크 내에서 최적의 local sparse 구조를 dense components로 근사할 필요성이 있는데, 이 논문에서 고안한 '최적의 lcoal sparse 구조를 dense components로 근사하는 방법'이 바로 인셉션 모듈이다.
📌 인셉션 모듈
✔ 인셉션 모듈
1. 인셉션 모듈은 입력에 대해 1x1, 3x3, 5x5 convolutions 및 3x3 max pooling을 병렬적으로 수행하여 다양한 features를 추출한다. 이미지에 존재하는 수많은 single region(local한 각 부분들)을 파악하기 위해 1x1 convolutions을 사용하고, 이미지에서 large regions(좀 더 global한 부분들, spatially spread out clusters)를 파악하기 위해 3x3, 5x5 convolutions를 사용한다.
2. 1x1, 3x3, 5x5 convolutions 및 3x3 max pooling을 병렬적으로 수행한 각각의 결과를 channel-wise로 concatenation하여 출력한다.
3. 즉 인셉션 모듈은 다양한 filter sizes의 convolutions를 병렬적으로 수행하는 방식을 통해 네트워크 연결의 sparsity를 확보하고, 이렇게 다양한 filter sizes의 convolutions를 수행하여 그 결과를 channel 방향으로 concat 연산하는 방식을 통해 dense components로의 근사를 가능하게 한다.
✔ naive 버전의 인셉션 모듈의 문제점
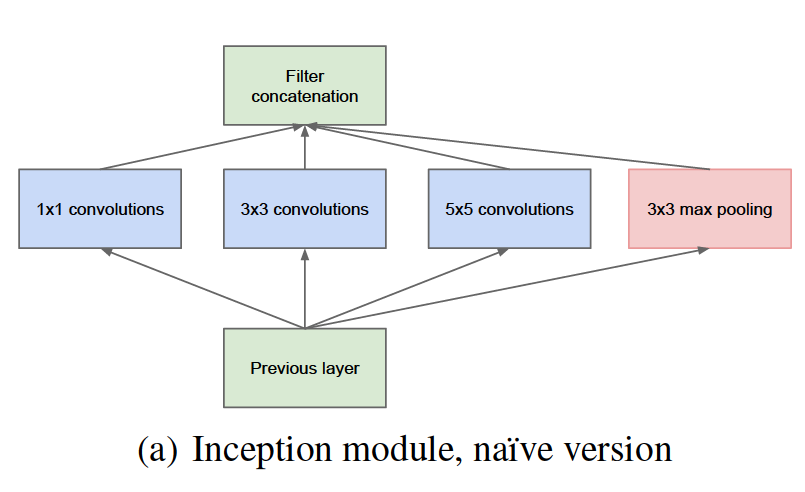
네트워크에서 출력층에 더 가까운 레이어일수록 고차원으로 추상화된 특징들을 잘 포착하게 되어 spatial concentration이 떨어지므로, 3x3, 5x5 convolutions의 비율을 증가시켜야 한다. 그런데 이렇게 3x3, 5x5 convolutions의 비율을 늘리는 구조는 연산량이 지나치게 많고 비효율적이다. 적당량의 5x5 convolutions을 사용하더라도 필터 개수가 많을 경우 그 연산 비용이 크게 증가하고, pooling units가 더해지면 이 문제가 더 부각된다. 즉 naive 버전의 인셉션 모듈은 지나치게 파라미터 개수가 많아져서 연산량이 크게 늘어나는 문제가 있다. 이에 대한 해결방법으로, 3x3, 5x5 convolutions 이전에 1x1 convolutions를 수행하는 bottleneck layers를 도입하게 된다.
✔ 1x1 convolutions을 수행하는 bottileneck layers를 도입

3x3, 5x5 convolutions 수행 전에 1x1 convolutions를 통해 차원을 축소하면 파라미터 개수가 줄어들고 그로 인해 연산량도 감소하는 효과가 있다.
예를 들어서 14x14x480의 입력에 대해 48개 filters의 5x5 convolution이 이루어질 때 그 파라미터 개수는 (14x14x48) x (5x5x480) 으로 총 112.9M 개이다. 그런데 5x5 convolution 이전에 16개 filters를 가진 1x1 convolution을 거치면 파라미터 개수는 (14x14x16) x (1x1x480) + (14x14x48) x (5x5x16) 으로 총 5.3M 개이므로 파라미터 개수를 크게 줄일 수 있다.
또한 1x1 convolutions 시 ReLU 함수도 같이 적용되기 때문에 비선형성(non-linearity)을 더 확보하는 장점이 있다.
📌 GoogLeNet의 구조
✔ GoogLeNet의 구조
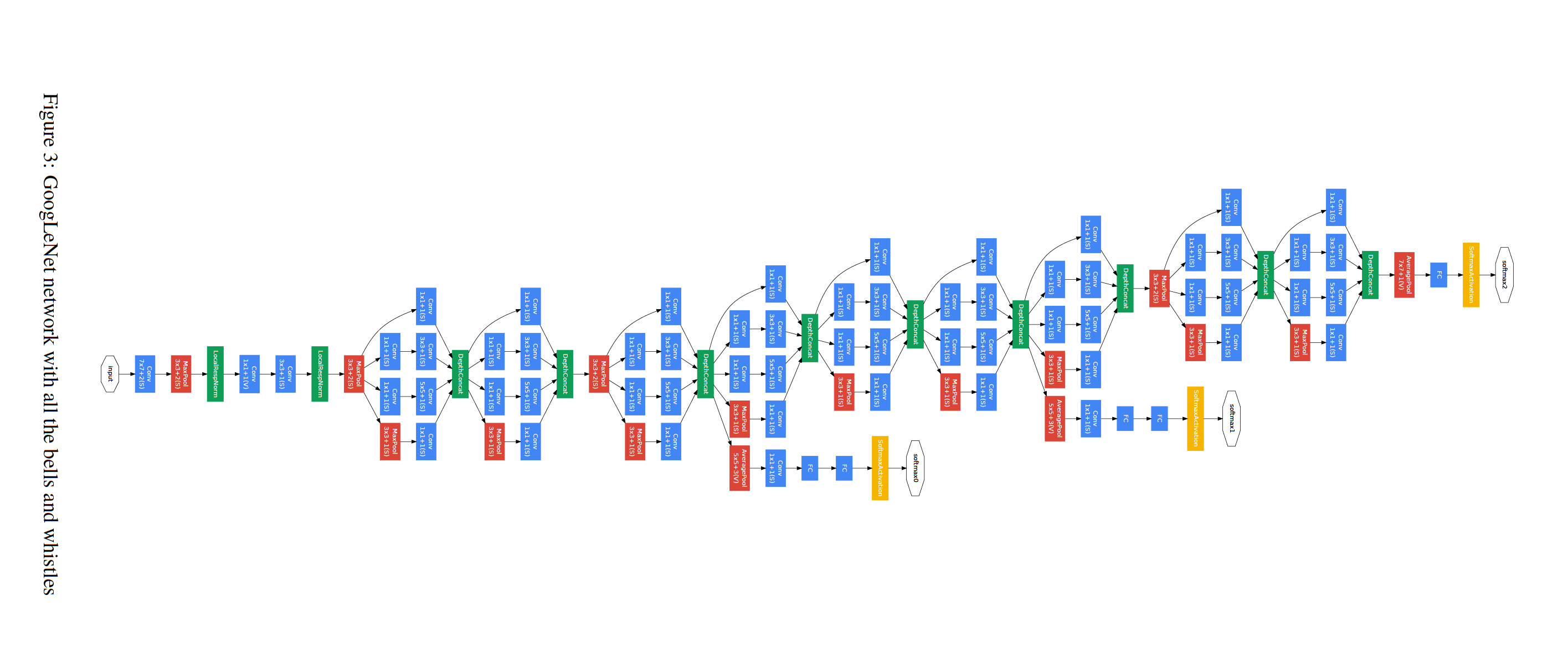
GoogLeNet은 22개 layers(pooling layers를 포함하면 27개 layers)를 쌓아 depth를 깊게 만들었으며, 9개의 인셉션 모듈이 반복되는 구조이다. Feature Extractor에서 Classifier로 넘어가기 전에 FC Layer 대신 Global Average Pooling Layer를 사용하였다. 또한 중간중간에 Auxiliary Classifier를 도입하였다.
✔ GoogLeNet의 각 Layer에 대한 설명 및 parameter 개수

📌 Global Average Pooling
✔ Global Average Pooling

1. 이전의 AlexNet은 Feature Extractor에서 Classifier로 넘어가기 전에 Flatten을 통해 Fully Connected Layer를 사용하였는데 파라미터가 많아 연산량이 많아지는 단점, 위치 정보가 소실되는 단점이 있었다.
2. GoogLeNet에서 새롭게 도입한 Global Average Pooling은 단순히 개별 feature map별로 평균값을 구하는 것이므로 파라미터가 필요하지 않아 연산량이 줄어들고 overfitting을 방지할 수 있다. 또한 FC Layer는 CNN의 Feature Extractor와 Classifier 사이에서 블랙박스와 같았으나, Global Average Pooling은 각 feature map별 정보가 최종 분류값과 대응하므로 상대적으로 더 명확하고 해석 가능한 결과를 가져올 수 있다.
3. FC Layer를 사용할 때보다 Global Average Pooling을 사용하였을 때 top-1 accuracy가 0.6% 향상.
📌 Auxiliary Classifier
✔ Auxiliary Classifier
1. GoogLeNet에서 중간중간에 Auxiliary Clasifier가 2개 존재하는데, 네트워크가 깊어질수록 training 과정에서 vanishing gradient 문제가 발생하는 것을 해결하기 위해 도입.
2. inference 시에는 이 부분을 사용하지 않음.
논문 링크 : https://arxiv.org/pdf/1409.4842.pdf



